Welcome to Learn2Clean’s documentation¶

Learn2Clean: The Python library for optimizing data preprocessing and cleaning pipelines based on Q-Learning
Overview¶
Learn2Clean is a Python library for data preprocessing and cleaning based on Q-Learning, a model-free reinforcement learning technique. It selects, for a given dataset, a ML model, and a quality performance metric, the optimal sequence of tasks for preperaring the data such that the quality of the ML model result is maximized.
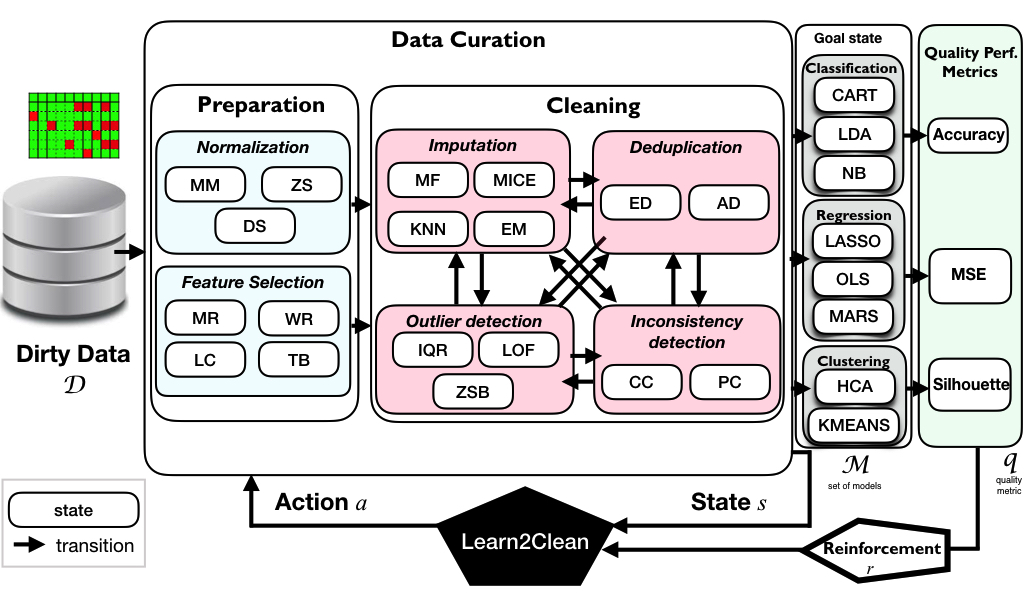
In Learn2CLean, various types of representative preprocessing techniques can be used for:
- Normalization. Min-Max (MM), Z-score (ZS), and decimal scale normalization (DS);
- Feature selection. based on a user-defined acceptable ratio of missing values (MR), removing collinear features (LC), using a wrapper subset evaluator (WR), and a model-based classifier for feature selection (Tree-Based or SVC);
- Imputation. Expectation-Maximization (EM), K-Nearest Neighbours, Multiple Imputation by Chained Equations (MICE), and replacement by the most frequent value (MF);
- Outlier detection. Inter Quartile Range (IQR), the Z-score-based method (ZSB), Local Outlier Factor (LOF);
- Deduplication. Exact duplicate (ED) and approximate duplicate (AD) detection based on Jaccard similarity distance;
- Consistency checking. Two methods based on constraint discovery and checking (CC) and pattern checking (PC).
Links¶
- Tutorial:
- Laure Berti-Equille. ML to Data Management: A Round Trip. Tutorial Part I, ICDE 2018. Tutorial
- Article:
Laure Berti-Equille. Learn2Clean: Optimizing the Sequence of Tasks for Web Data Preparation. Proceedings of the Web Conf 2019, San Francisco, May 2019. Preprint
[BibTeX] @inproceedings{Berti-Equille2019, author = {Berti-Equille, Laure}, title = {Learn2Clean: Optimizing the Sequence of Tasks for Web Data Preparation}, booktitle = {Proceedings of the 2019 World Wide Web Conference}, series = {WWW '19}, year = {2019}, location = {San Francisco, CA, USA}, url = {https://doi.org/10.1145/3308558.3313602}, doi = {10.1145/3308558.3313602}, publisher = {International World Wide Web Conferences Steering Committee} }